- We warmly welcome potential speakers to join us at ICML 2026 Workshop, The 3rd Efficient Computing under Limited Resources: Modern AI Models and Systems. Past workshop homepages: 2nd at ICCV 2025, 1st at ACM MM 2024.
- One paper accepted by ICLR 2026: "QVGen: Pushing the Limit of Quantized Video Generative Models". Congratulations to Yushi Huang!
- A GitHub repository of Edge LLMs Awesome-Edge-LLMs collecting papers, deployment toolchains, frameworks, whitebooks about large language models on edge scenarios.
- One paper accepted by ICML 2025: "DA-KD: Difficulty-Aware Knowledge Distillation for Efficient Large Language Models". Congratulations to Changyi He!
- One paper accepted by ACL 2025: "Dynamic Parallel Tree Search for Efficient LLM Reasoning".
- One paper accepted by IJCAI 2025: "Unlocking the Potential of Lightweight Quantized Models for Deepfake Detection". Congratulations to Ziheng Qin!
- One paper accepted by NeurIPS 2025: "VORTA: Efficient Video Diffusion via Routing Sparse Attention". Congratulations to Wenhao Sun!
Welcome to Yifu's homepage.
Leave your curiosity for the world, and let time deliver the answers.
Bio: PhD Candidate at Beihang University & Nanyang Technological University (joint programme).
Supervised by Prof. Xianglong Liu and Prof. Dacheng Tao.
Research focus: model compression and inference efficiency.
Bachelor's degree Graduated 2021.
Ph.D Enrolled Sep 2021 · Expected graduation Jun 2027.
Updates
Recent Papers
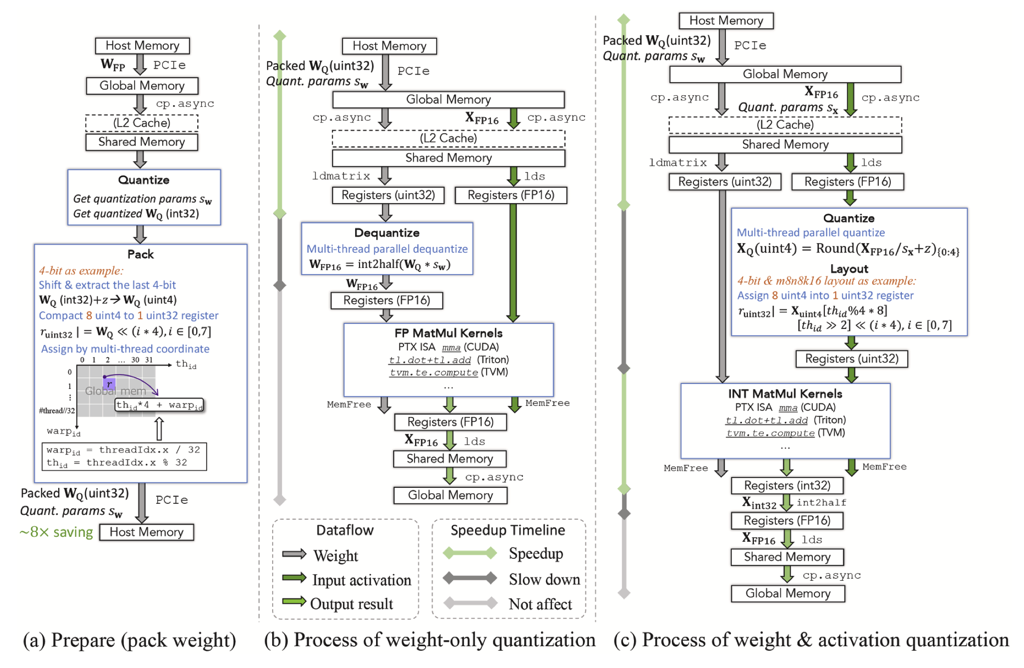
A survey of low-bit large language models: Basics, systems, and algorithms
This survey reviews low-bit quantization for large language models, covering core principles, data formats, system support, and algorithmic methods. It highlights how low-bit techniques reduce memory and computation costs while preserving performance.
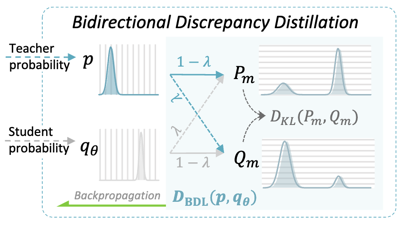
DA-KD: Difficulty-Aware Knowledge Distillation for Efficient Large Language Models
DA-KD reduces distillation cost by dynamically selecting training samples based on difficulty. It introduces bidirectional discrepancy loss to stabilize optimization, achieving 2% accuracy gain with half training cost and 4.7× compression.
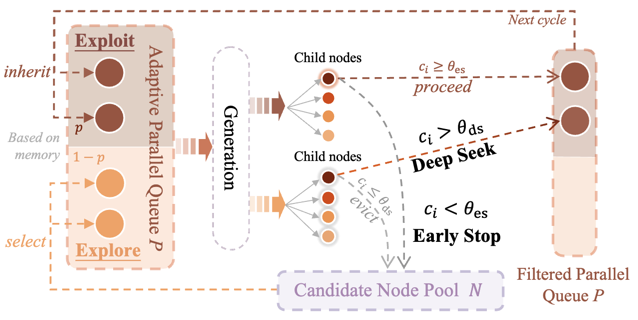
Dynamic Parallel Tree Search for Efficient LLM Reasoning
DPTS accelerates Tree of Thoughts reasoning by reducing redundant exploration and focus switching. It introduces parallelism streamline for flexible multi-path generation and search mechanism to keep focused. Achieves 2-4× speedup on Qwen-2.5 and Llama-3.
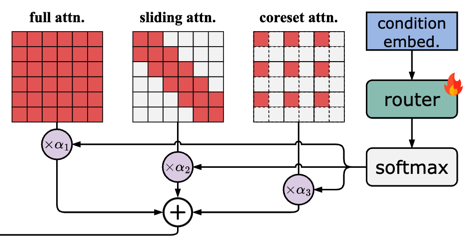
VORTA: Efficient Video Diffusion via Routing Sparse Attention
VORTA accelerates video diffusion transformers using sparse attention for long-range dependencies and routing to replace full 3D attention. It achieves 1.76× speedup on VBench and composes with other methods to reach 14.41× speedup.
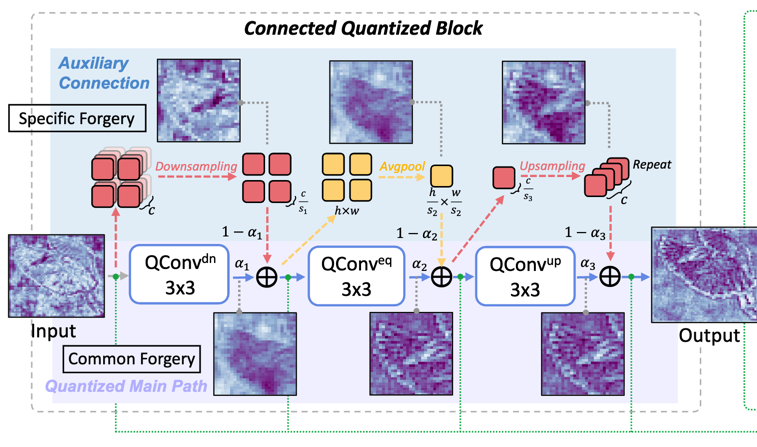
Unlocking the Potential of Lightweight Quantized Models for Deepfake Detection
This work targets real-time edge deepfake detection via low-bit quantization. A Connected Quantized Block captures shared forgery features while preserving textures. Results show 10.8× compute and 12.4× storage reduction with strong accuracy.
Workshop Services
- Program Chair at the 3rd ECLR workshop: Efficient Computing under Limited Resources: Modern AI Models and Systems at ICML 2026 (⭐️Proposal submitted. Speaker invitations are still open.⭐️).
- My lab colleagues held the 6th Workshop of Adversarial Machine Learning on Computer Vision: Safety of Vision-Language Agents at CVPR 2026. Welcome to follow!
- Program Chair at the 2nd Workshop on Efficient Computing under Limited Resources: Visual Computing at ICCV 2025. Responsible for full process coordination, including workshop promotion, reviewer assignment, decision organization, and final camera-ready metadata submission.
- My lab colleagues held the 3rd International Workshop on Generalizing from Limited Resources in the Open World at IJCAI 2025. Welcome to follow!
- Local Arrangement Chair at the 2nd International Workshop on Generalizing from Limited Resources in the Open World at IJCAI 2024. Responsible for on-site logistics and coordination to ensure smooth conference operations.
- Publicity Chair at the 1st International Workshop on Efficient Multimedia Computing under Limited Resources at ACM MM 2024.
Customized Tools
- English Vocabulary iOS App: A vocabulary learning app based on etymology tracing. Features four-stage memory training system, offline dictionary, and comprehensive word root analysis. GitHub.
- Conference Workshop Proposal Template: A LaTeX template for conference workshop proposals, based on successful proposals from previous workshops. Includes compact and full versions. GitHub.
- Journal Response Template: A LaTeX template for journal response letters. Supports structured responses to editors and reviewers with track changes functionality. GitHub.